



データアーキテクチャとは
データアーキテクチャは、組織のデータ収集、管理、および使用を記述および管理する包括的なフレームワークです。今日の組織は、さまざまなデータソースから膨大な量のデータを受け取っており、さまざまなチームが分析、機械学習、人工知能、その他のアプリケーションのためにそのデータにアクセスしたいと考えています。最新のデータアーキテクチャは、データのセキュリティと品質を確保しながら、データにアクセスして使用できる、一貫したシステムを提供します。ポリシー、データモデル、プロセス、テクノロジーを定義することで、組織がデータを部門間で簡単に移動し、必要なときにいつでも利用できるようにすると同時に (リアルタイムアクセスを含む)、規制コンプライアンスを完全にサポートできます。
データアーキテクチャのコンポーネントとは何ですか?
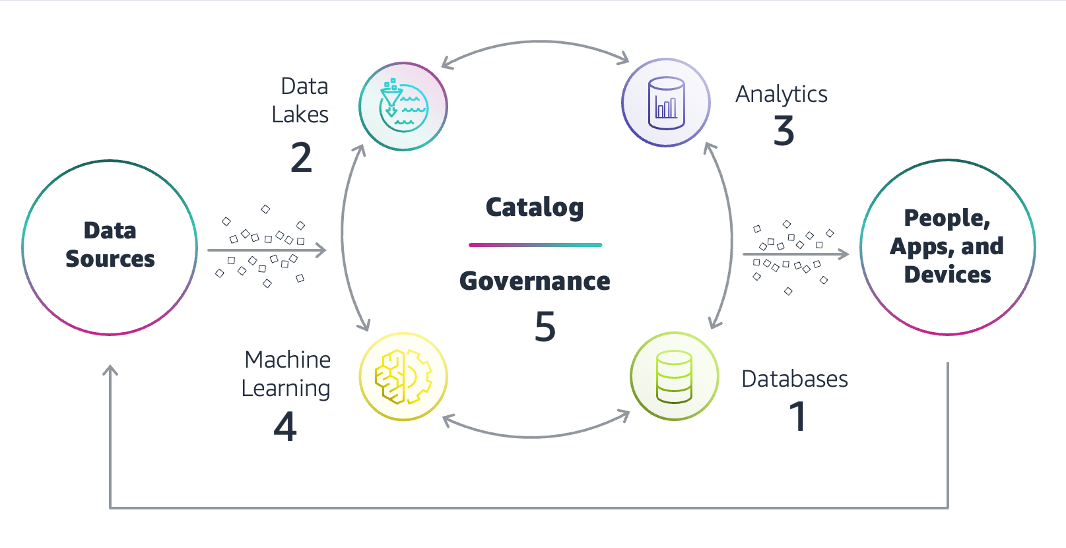
主なデータアーキテクチャコンポーネントを以下に示します。
データソース
データソースには、顧客向けアプリケーション、監視およびテレメトリシステム、IoT デバイスとスマートセンサー、事業運営をサポートするアプリ、社内ナレッジストア、データアーカイブ、サードパーティデータストアなどがあります。構造化データと非構造化データの両方が、さまざまな速度、量、頻度で組織に流入します。
データベース
目的別データベースシステムは、最新のアプリケーションとそのさまざまな機能をサポートします。リレーショナルでも非リレーショナルでもよく、データを構造化されたテーブルとして保存するものもあれば、非構造化データタイプをドキュメントまたはキーと値のペアとして保存するものもあります。 データベースには通常、特定のユースケースに関連するドメイン固有のデータが格納されます。ただし、データは現在のシステム以外でも使用できます。たとえば、顧客向けアプリのデータは、マーケティング分析や計画に使用でき、処理するにはデータベースから取り出す必要があります。同様に、他の場所から処理されたデータは、分析または機械学習 (ML) アプリケーションのデータベースに再ロードする必要があります。
データレイク
データレイクは、大規模な未加工データストレージのための一元化されたリポジトリです。データアーキテクチャは、データをさまざまなデータベースからデータレイクに移動し、必要に応じてさまざまなデータベースに戻す方法を記述します。データレイクはデータをネイティブ形式またはオープン形式で保存するため、使用前にフォーマットやクリーニングを行うことができます。データ統合をサポートし、組織内のデータサイロを解消します。
データ分析
データ分析コンポーネントには、従来のデータウェアハウス、バッチレポート、およびリアルタイムのアラートとレポート用のデータストリーミングテクノロジーが含まれます。これらは、1 回限りのクエリや高度な分析のユースケースに使用できます。データアーキテクチャによってデータへのアクセスが容易になり、誰もが組織のデータ資産をより自由に使用できるようになるため、分析がデータサイロに縛られることはありません。
人工知能
機械学習と AI は、組織が将来のシナリオを予測し、アプリケーションにインテリジェンスを組み込むのに役立つ最新のデータ戦略にとって不可欠です。データサイエンティストは、レイクから集められたデータを使用して実験を行い、インテリジェンスのユースケースを特定し、新しいモデルをトレーニングします。トレーニング後も、AI モデルは関連性のある有用なアウトプットを生み出すために、最新のデータに継続的にアクセスする必要があります。最新のデータアーキテクチャには、AI モデルトレーニングと推論をサポートするすべてのテクノロジーとインフラストラクチャが含まれています。
データガバナンス
データガバナンスは、データの利用に関する役割、責任、基準を決定します。どのユーザーが、どのデータに対して、どのような方法を使用して、どのような状況で、どのようなアクションを実行できるかの概要を定めます。データ品質とデータセキュリティ管理の両方が含まれます。データアーキテクトは、継続的な規制遵守のためにデータ使用状況を監査および追跡するプロセスを定義します。
メタデータ管理はデータガバナンスの不可欠な部分です。データアーキテクチャには、メタデータを保存および共有するためのツールとポリシーが含まれています。さまざまなシステムがメタデータを保存および検出し、データ資産のさらなるクエリと処理に使用できる、中央のメタデータストアを提供するメカニズムについて概説しています。
データアーキテクチャはどのように実装されていますか?
最新のデータアーキテクチャをレイヤーで実装するのがベストプラクティスです。レイヤーは、明確な目的に基づいてプロセスとテクノロジーをグループ化します。実装の詳細は柔軟ですが、テクノロジーの選択と統合方法の指針となるのはレイヤーです。

ステージングレイヤー
ステージングレイヤーは、アーキテクチャ内のデータのエントリポイントです。構造化、半構造化、非構造化などの形式で、さまざまなソースからの生データインジェストを処理します。このレイヤーはできるだけ柔軟にする必要があります。
このレイヤーでスキーマ (データ形式とタイプ) を厳密に強制すれば、下流のユースケースは限定的になります。たとえば、すべての日付値を月、年の形式として強制すると、dd/mm/yyyy 形式を必要とする将来のユースケースが制限されます。同時に、ある程度の一貫性も必要です。たとえば、電話番号を文字列として保存してそのまま使用しても、他のデータソースが数値と同じデータを生成し始めると、データパイプラインが中断します。
柔軟性と一貫性のバランスを取るには、このレイヤーを 2 つのサブレイヤーに分割する必要があります。
未加工のレイヤー
未加工のレイヤーには、変更されていないデータが到着したとおりに格納され、元の形式と構造が変換されずに保持されます。これは、データの調査、監査、および再現性のための、企業全体のリポジトリです。チームは必要に応じて元の状態のデータを再検討して分析できるため、透明性とトレーサビリティを保持できます。
標準化されたレイヤー
標準化されたレイヤーは、事前定義された標準に従って検証と変換を適用することにより、生データを使用できるように準備します。たとえば、このレイヤーでは、すべての電話番号が文字列に変換され、すべての時間値が特定の形式に変換されます。これにより、組織内のすべてのユーザーが、構造化された品質が保証されたデータにアクセスするためのインターフェースになります。
データアーキテクチャの標準化されたレイヤーは、セルフサービスビジネスインテリジェンス (BI)、ルーチン分析、ML ワークフローを実現するために不可欠です。スキーマの変更による混乱を最小限に抑えながら、スキーマ標準を適用します。
適合レイヤー
さまざまなソースからのデータ統合は、適合レイヤーで完了します。これにより、ドメイン全体で統一されたエンタープライズデータモデルが作成されます。たとえば、顧客データは部門によって詳細が異なる場合があります。オーダーの詳細は営業が、財務履歴は取引先が、関心やオンラインアクティビティはマーケティング部門によって取得されます。適合レイヤーにより、このようなデータを組織全体で理解できるようになります。主な利点は次のとおりです:
- 組織全体にわたる中核エンティティの一貫した統一された定義。
- データセキュリティおよびプライバシー規制の遵守。
- 企業全体の統一性と、一元化された分散パターンによるドメイン固有のカスタマイズとのバランスをとる柔軟性。
オペレーショナルビジネスインテリジェンスには直接使用されませんが、探索的データ分析、セルフサービス BI、およびドメイン固有のデータエンリッチメントをサポートします。
エンリッチドレイヤー
このレイヤーは、前のレイヤーのデータを、特定のユースケースに合わせたデータプロダクトと呼ばれるデータセットに変換します。データ製品は、日々の意思決定に使用される運用ダッシュボードから、パーソナライズされた推奨事項やネクストベストアクションのインサイトが充実した詳細な顧客プロファイルまで、多岐にわたります。これらは、特定のユースケースに基づいて選択されたさまざまなデータベースまたはアプリケーションでホストされています。
組織は、他のチームが発見したりアクセスしたりできるように、一元化されたデータ管理システムにデータ製品をカタログ化します。これにより、冗長性が減り、高品質で豊富なデータに簡単にアクセスできるようになります。
データアーキテクチャにはどのような種類がありますか?
適合層には、異なるデータアーキテクチャタイプを作成する 2 つの異なるアプローチがあります。
一元化されたデータアーキテクチャ
一元化されたデータアーキテクチャでは、適合層は、企業全体で広く使用される顧客や製品などの共通エンティティの作成と管理に重点を置きます。エンティティは、データ管理が容易で適用範囲が広いため、限定された汎用属性セットで定義されています。たとえば、顧客エンティティには、名前、年齢、職業、住所などのコア属性が含まれる場合があります。
このようなデータアーキテクチャは、特に個人を特定できる情報 (PII) 支払いカード情報 (PCI) などの機密情報の一元的なデータガバナンスをサポートします。一元化されたメタデータ管理により、データのカタログ化と管理が効果的に行われ、系統追跡とライフサイクル制御により透明性とセキュリティが確保されます。
ただし、複雑なデータ要件を一元管理すると意思決定とイノベーションが遅くなるため、このモデルでは考えられるすべての属性を含めることを避けています。代わりに、顧客キャンペーンのインプレッション (マーケティングでのみ必要) などのドメイン固有のプロパティが、それぞれのビジネスユニットによってエンリッチドレイヤーで導出されます。
データファブリックテクノロジーは、一元化されたデータアーキテクチャを実装するのに役立ちます。
分散データアーキテクチャ
各ドメインは、分散データアーキテクチャで独自の適合レイヤーを作成して管理します。たとえば、マーケティングは顧客セグメント、キャンペーンのインプレッション、コンバージョンなどの属性に重点を置き、会計では注文、収益、純利益などのプロパティを優先します。
分散データアーキテクチャでは、エンティティとそのプロパティを柔軟に定義できますが、共通エンティティのデータセットは複数になります。これらの分散データセットの検出とガバナンスは、中央のメタデータカタログを通じて実現されます。利害関係者は、データ交換プロセスを監視しながら、適切なデータセットを見つけて使用できます。
データメッシュテクノロジーは、分散データアーキテクチャの実装に役立ちます。
データアーキテクチャフレームワークとは
データアーキテクチャフレームワークは、データアーキテクチャを設計するための構造化されたアプローチです。組織のビジネス目標に沿った効率的なデータ管理プロセスを保証する一連の原則、標準、モデル、およびツールを提供します。これは、データアーキテクトが高品質で包括的なデータアーキテクチャを構築するために使用する標準的なブループリントと考えることができます。
データアーキテクチャフレームワークの例には、次のようなものがあります
DAMA-DMBOK フレームワーク
データ管理知識体系 (DAMA-DMBOK) フレームワークは、ライフサイクル全体にわたる効果的なデータ管理のためのベストプラクティス、原則、およびプロセスの概要を示しています。ビジネス目標との整合性を確保しながら、一貫したデータ管理慣行の確立をサポートします。DAMA-DMBOK は、データ資産を戦略的リソースとして扱うことで、意思決定と業務効率を向上させるための実用的なガイダンスを提供します。
Zachman フレームワーク
Zachman フレームワークは、マトリックス形式を使用してさまざまな視点 (ビジネスオーナー、デザイナー、ビルダーなど) と 6 つの主要な質問 (何を、どこで、誰が、いつ、なぜ、どのように)の関係を定義するエンタープライズアーキテクチャフレームワークです。組織は、データが業務全体にどのように当てはまるかを視覚化し、データ関連のプロセスがビジネス目標やシステム要件と一致していることを確認できます。Zachman フレームワークは、企業全体のデータやシステムの依存関係を明確にする能力があることで広く知られています。
TOGAF
Open Group Architecture Framework (TOGAF) は、データアーキテクチャをより広範なシステムの重要なコンポーネントとして扱い、組織のニーズをサポートするデータモデル、データフロー、ガバナンス構造の作成に重点を置いています。標準化されたデータプロセスを確立し、システムの相互運用性と効率的なデータ管理を保証します。これは、統一されたアプローチを通じて IT 戦略とビジネス戦略を連携させたいと考えている大企業にとって特に有益です。
データアーキテクチャと、他の関連する用語との比較
さまざまなデータ用語は似ているように聞こえますが、意味はまったく異なります。以下にいくつか説明します。
データアーキテクチャと情報アーキテクチャ
情報アーキテクチャとは、情報を整理してエンドユーザーに提示することです。この用語は、ユーザーインターフェース、ウェブサイト、またはコンテンツシステムに適用され、エンドユーザー情報のアクセシビリティに関するものです。情報アーキテクチャの原則とツールは、たとえばオンラインナレッジストアやドキュメントデータベース内でのナビゲーション、分類、検索のしやすさに重点を置いています。
対照的に、データアーキテクチャはすべての組織データの設計と管理に重点を置いています。すべてのバックエンドの技術データインフラストラクチャを扱っていますが、情報アーキテクチャはエンドユーザーが情報をどのように扱い、解釈するかにのみ焦点を当てています。
データアーキテクチャとデータエンジニアリング
データエンジニアリングは、データアーキテクチャの実用的な実装です。データアーキテクトは、組織のデータ資産を管理するための大まかな計画を提供します。ビジネス目標とセキュリティポリシーに沿ったスケーラブルなデータシステムを設計します。データエンジニアは、データパイプラインの構築、保守、最適化という計画を実行します。これにより、データアーキテクチャのルールに従って、データの取り込み、クリーニング、変換、分析のための配信が保証されます。
データアーキテクチャとデータモデリング
データモデリングは、あらゆるデータコレクションを視覚的に表現するデータアーキテクチャ内のプロセスです。これには、コレクション内のデータの概要を示す概念的、論理的、および物理的なデータモデルの作成が含まれます。理論データモデルは、プラットフォームに依存しない方法で実装するためのデータ制約、エンティティ名、および関係を図式的に表します。物理モデルは、特定のデータテクノロジーに実装するための論理データモデルをさらに洗練させます。
データアーキテクチャの対象範囲は、データモデリングだけにとどまりません。データの属性と関係だけでなく、組織全体のデータ管理のためのより広範な戦略も定義します。これには、組織の目標に沿ったデータ統合のためのインフラストラクチャ、ポリシー、テクノロジーが含まれています。
AWS はデータアーキテクチャの要件をどのようにサポートできますか?
AWS は、ストレージや管理からデータガバナンスや AI まで、データアーキテクチャのあらゆるレイヤーに対応する包括的な分析サービスを提供しています。AWS は、最高のコストパフォーマンス、スケーラビリティ、最低コストで目的に合わせたサービスを提供します。例:
- AWS のデータベースには、さまざまなリレーショナルデータモデルと非リレーショナルデータモデルをサポートする 15 を超える目的別データベースサービスが含まれています。
- AWS 上でのデータレイクには、無制限の未加工データストレージを提供し、安全なデータレイクを数か月ではなく数日で構築するサービスが含まれています。
- AWS とのデータ統合には、複数のソースからのデータをまとめるサービスが含まれているため、組織全体でデータを変換、運用、管理できます。
AWS Well-Architected は、クラウドデータアーキテクトが高い安全性、性能、障害耐性、効率性を備えたインフラストラクチャを構築する際に役立ちます。 AWS アーキテクチャセンターには、組織にさまざまな最新データアーキテクチャを実装するためのユースケースベースのガイドラインが含まれています。
今すぐ無料アカウントを作成して、AWS でデータアーキテクチャの使用を開始しましょう。